You Don't Know Embodied AI: From a Tiny Robot Dog to Optimus
Categories: Share

Short Version
In April I assembled a small robot dog. I posted a few clips on X while I was building it, so some of you probably saw the parts, the frame, and the final moment when it could hear a command, walk a couple of steps, and say a few lines back.
The idea started around Chinese New Year. I had been using Opus 4.6 to write code every day, and in many places it was faster and cleaner than I was. That gave me a bit of FOMO. I wanted to try something that crossed the software and hardware boundary, where there were still a few entry barriers beyond typing prompts and shipping code.
Once I decided to build something, the question quickly became practical: how do I read sensors, drive servos, handle communication failures, power the board, mount the parts, and deal with physical faults? Those questions were more concrete than “build a robot.” I bought an STM32, ASRPRO, ESP32-C3, MG90S servos, an OLED display, a DHT11 sensor, a lithium battery, and a set of 3D-printed parts. The goal was a small dog that could hear speech, lie down, walk, and connect to a cloud model for conversation.
The small details took the most time. One of the four MG90S servos was always a little unstable. I plugged the OLED in while powered and burned it out, then waited several more days for replacement parts. Only after the DeepSeek conversation, temperature and humidity reading, and motion control all worked on the real device did I start to feel what “AI entering the physical world” meant.
From a software point of view, embodied AI is easy to describe as a large model with a body attached. Once wires are plugged in, motors start moving, and the frame starts shaking, the feeling changes. A natural-language command has to pass through structured intent, action sequences, PWM, torque, current, and contact. Each layer has its own budget for time, energy, and error. A pile of problems appears that pure software usually never has to care about.
After I published my article on large models, a few friends joked that I should write one on embodied AI next. This little robot dog turned out to be a useful entry point. It is a simple toy-level system, but the concepts I wanted to understand, perception, space, action, and torque, all show up on it in small form.
The first half of this piece is about building that robot dog. The second half is my study notes from public papers, official blogs, open-source projects, and third-party technical write-ups. I hope it gives people outside the robotics field one more engineer’s angle on embodied AI.
First, Make the Robot Dog Run
The robot dog ended up as a low-cost heterogeneous system. The whole thing cost a little over RMB 200. It can hear a wake word, enter a dialogue, send the user’s command to a cloud LLM for semantic parsing, and convert the returned structured action into servo control commands that the STM32 can run.
| Module | Model or spec | Price range | What it does |
|---|---|---|---|
| Main controller | STM32F103C8T6 | CNY 5 to 10 | Servo control, sensor reading, basic motion logic |
| Offline speech | ASRPRO | CNY 15 to 25 | Wake word and local keyword recognition |
| Network module | ESP32-C3-MINI | CNY 10 to 15 | Wi-Fi, provisioning, cloud AI dialogue |
| Backup Wi-Fi | ESP-01S | CNY 8 to 12 | Backup communication channel |
| Servos | MG90S metal gear x 4 | CNY 40 to 60 | Angle control for the four legs |
| Sensor | DHT11 | CNY 5 to 10 | Temperature and humidity |
| Display | 0.96-inch OLED | CNY 10 to 15 | Status display |
| Power | 3.7V 1000mAh lithium battery | CNY 15 to 20 | Power supply |
| Body | 3D-printed PLA | CNY 20 to 30 | Body and four legs |
Breaking it into a data flow made debugging much easier. Many of the blocked points eventually landed around nearby hardware: false wake-ups, network timeouts, servo angles, unstable power. The hardware-side issues can almost be written as a troubleshooting table.
| Step | Input | Output | Common problems |
|---|---|---|---|
| Wake | Ambient audio | Wake event | False wake-ups, missed wake-ups, noise |
| Network | Wake event and user speech | Cloud request | Wi-Fi provisioning, disconnection, timeout |
| Intent parsing | Text or audio | Structured action | Parameter range, action name, context |
| Local communication | Structured action | UART frame | Checksum, packet loss, retry |
| Motion execution | UART frame | PWM output | Jitter, power, servo drift |
| Status return | Sensor data and execution result | Text or speech reply | Read delay, failure-state wording |
At first I wondered whether I should replace the small chips with one stronger chip and let it handle everything. Wiring the system changed that idea. Wake-up, networking, PWM, sensor reading, and cloud requests have different latency and stability requirements.
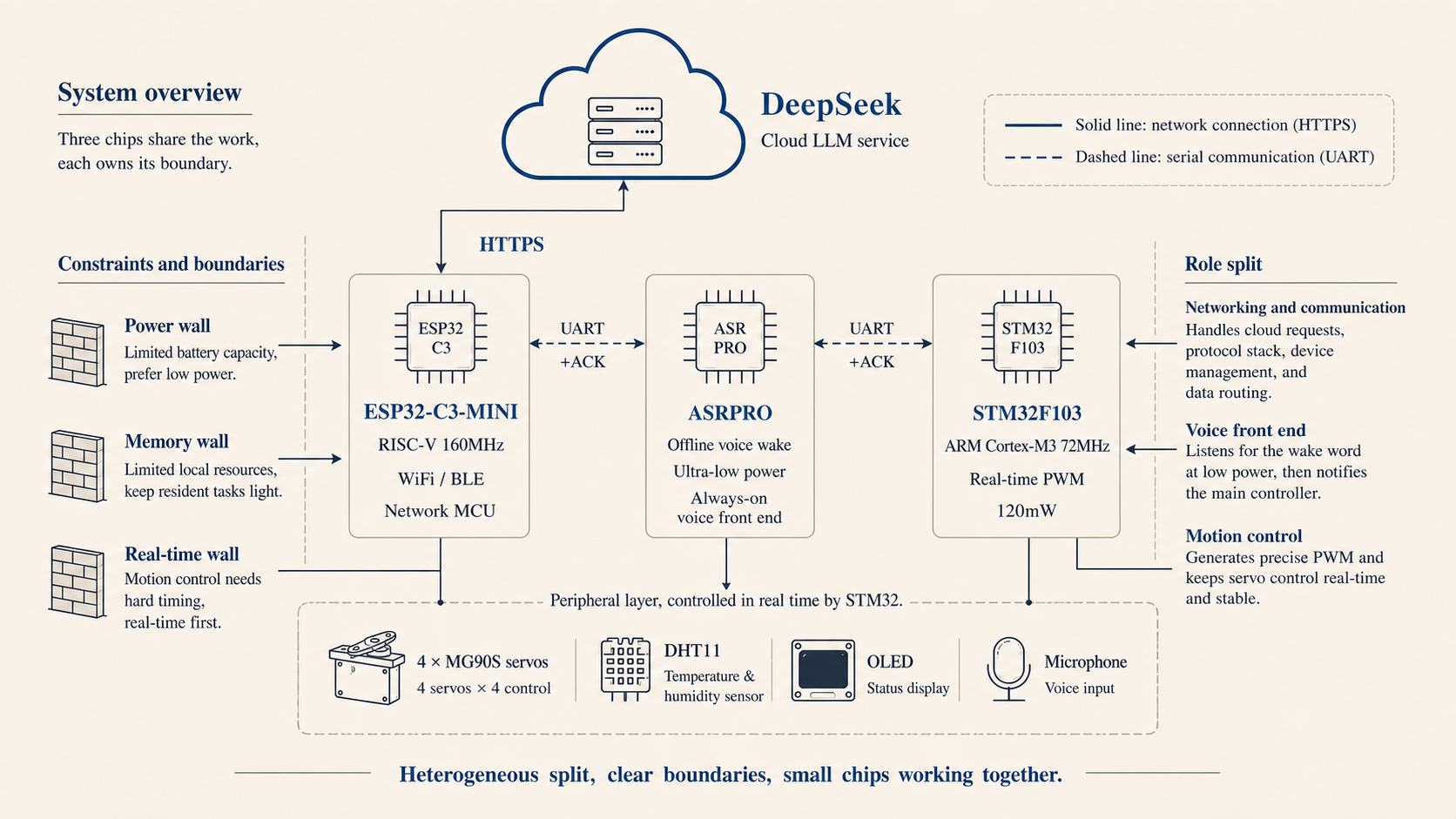
The ESP32-C3 handles Wi-Fi and cloud AI. It joins a 2.4 GHz network, forwards speech or text to the cloud model, and sends the result back to the STM32. It is a better fit for networking than the STM32, but if it also had to manage PWM, multiple UART links, network requests, and dialogue state, scheduling would quickly get heavy.
ASRPRO handles offline wake-up. It listens to the environment at low power, recognizes the wake word locally, and only then wakes the network path. That saves power and puts less privacy pressure on the system than uploading audio all the time.
The STM32F103 is a 72 MHz ARM Cortex-M3 with 64 KB of flash and 20 KB of SRAM. Running a model on it is unrealistic, but it is a good fit for hard real-time control. The four MG90S servos use 50 Hz PWM for angle control. A 0.5 to 2.5 ms pulse maps to 0 to 180 degrees. Hardware timers can output microsecond-level PWM steadily, so the walking motion is less likely to drift because of task scheduling.
The parts and tools all arrived on the Friday before the Qingming holiday. I started that night and spent the next few days on it. A pile of parts slowly became a wired-up little robot dog that could walk several steps and understand simple commands. It was a fun build.

|

|

|
I also used an MCP-like idea here, although in this small robot dog the implementation is much simpler. The model and the device share a list of capabilities. The device reports what it can do, and the model calls only what appears on that list.
The most useful part for me was separating local abilities from cloud abilities. The device controls local hardware such as the speaker, LED, servos, and GPIO. The cloud can extend to smart-home control, PC actions, knowledge search, email, and other higher-level tools. Once that line is drawn, the system boundary becomes easier to reason about.
A complete run looks like this. The ESP32-C3 first reports its capabilities, such as servo_control, sensor_read, and gpio_write. I say “Mambo, sit down.” The cloud model generates a structured call with the target servo, target angle, and speed parameters. The ESP32-C3 translates that into a UART command for the STM32. The STM32 then adjusts PWM step by step and reports execution status.
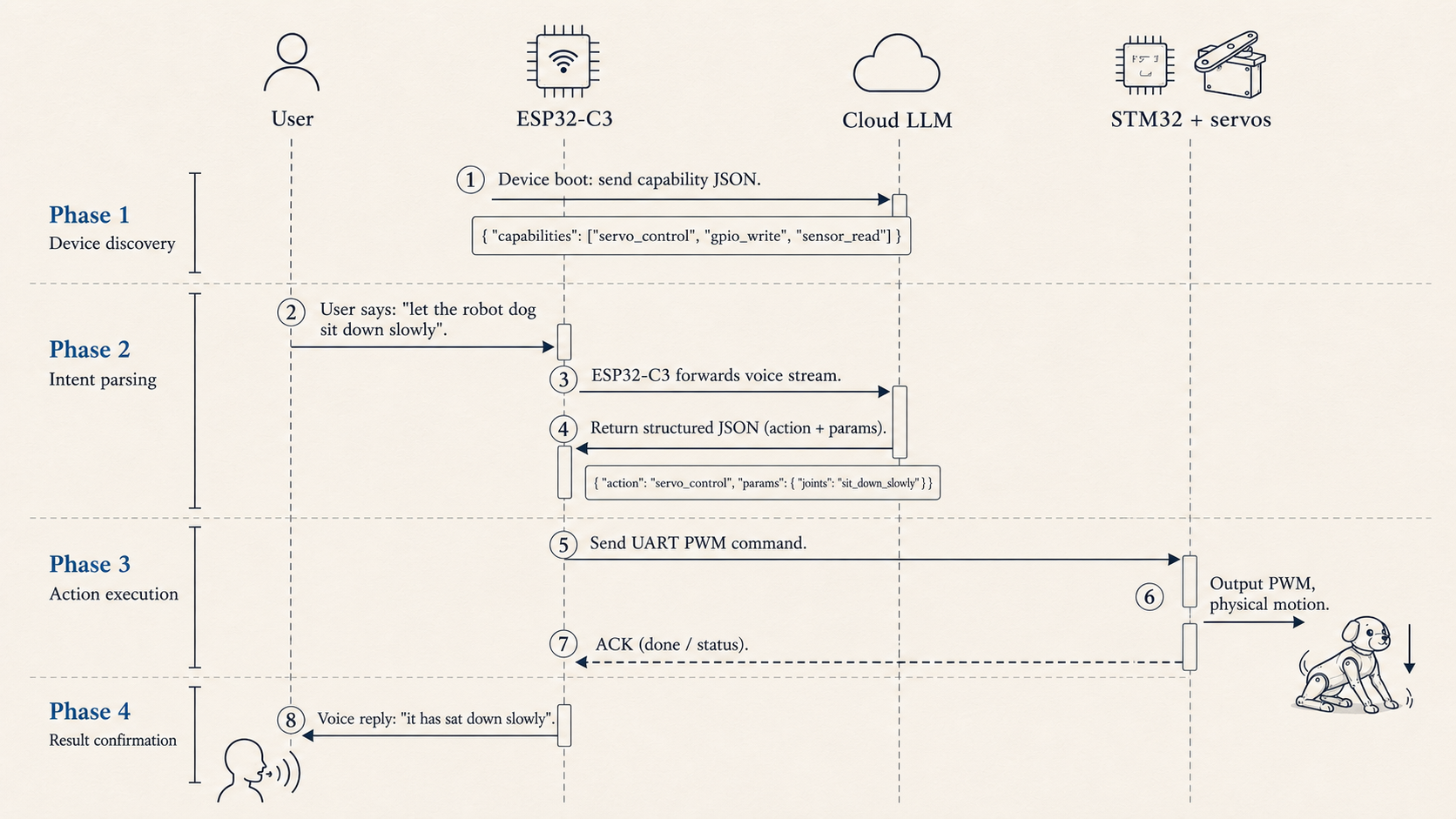
This small system can already understand “sit down,” “stand up,” and “what is the temperature now.” What it lacks is space. It does not know where it is, where the chair is, or whether taking two steps left will hit something. Once command intake, motor driving, and status return are working, spatial perception and action generation become much easier to think about.
How Does a Robot Know Where It Is?
My robot dog cannot understand “move two steps left around the chair.” It does not know how far the chair is. It does not know where it stands in the room or which way it is facing. It does not have a 3D map that updates over time. It lacks depth perception, pose estimation, and spatial mapping.
Adding spatial ability is not as simple as attaching another module. Once a depth camera, IMU, and a board capable of SLAM enter the system, the cost, power draw, and software stack all change. The STM32-based system cannot absorb that whole layer by itself.
Four new chains appear. Camera calibration has to handle intrinsics, distortion, exposure, and synchronization. Pose estimation has to resolve the transforms between the camera, IMU, and body frame. Map updating has to decide when an old map becomes invalid or needs correction. Motion planning has to remember that a reachable point on the map does not guarantee that the foot can land there stably.
A tabletop demo can avoid many of these problems. A room cannot. Reflective floors, table legs, cables, steps, and lighting changes all enter the system.
Image models are good at answering a 2D question: what is in this image? A robot has to keep going. How far away is the object? What is occluding it? Which direction gives a more stable grasp? After moving one step, how will the viewpoint and support points change?
In a 2D image, a cup is a few hundred pixels. In a robot’s world, a cup is an object with volume, weight, friction, occlusion, and contact surfaces. These are the 3D representations I kept seeing in robotics, each with a different engineering cost.
| Representation | Problem it solves | Engineering cost |
|---|---|---|
| Occupancy or voxel | Which spaces are occupied and where the robot can move | Needs multi-view input or depth estimation, with a trade-off between resolution and compute |
| Point cloud | Native 3D geometry from sensors | Sparse and unordered, with high cost for semantic processing |
| NeRF or 3D Gaussian Splatting | High-fidelity scene reconstruction and new-view synthesis | Training, updating, and dynamic objects are still hard |
| 3D scene graph | Spatial memory of rooms, objects, and relationships | Depends on stable perception and semantic binding |
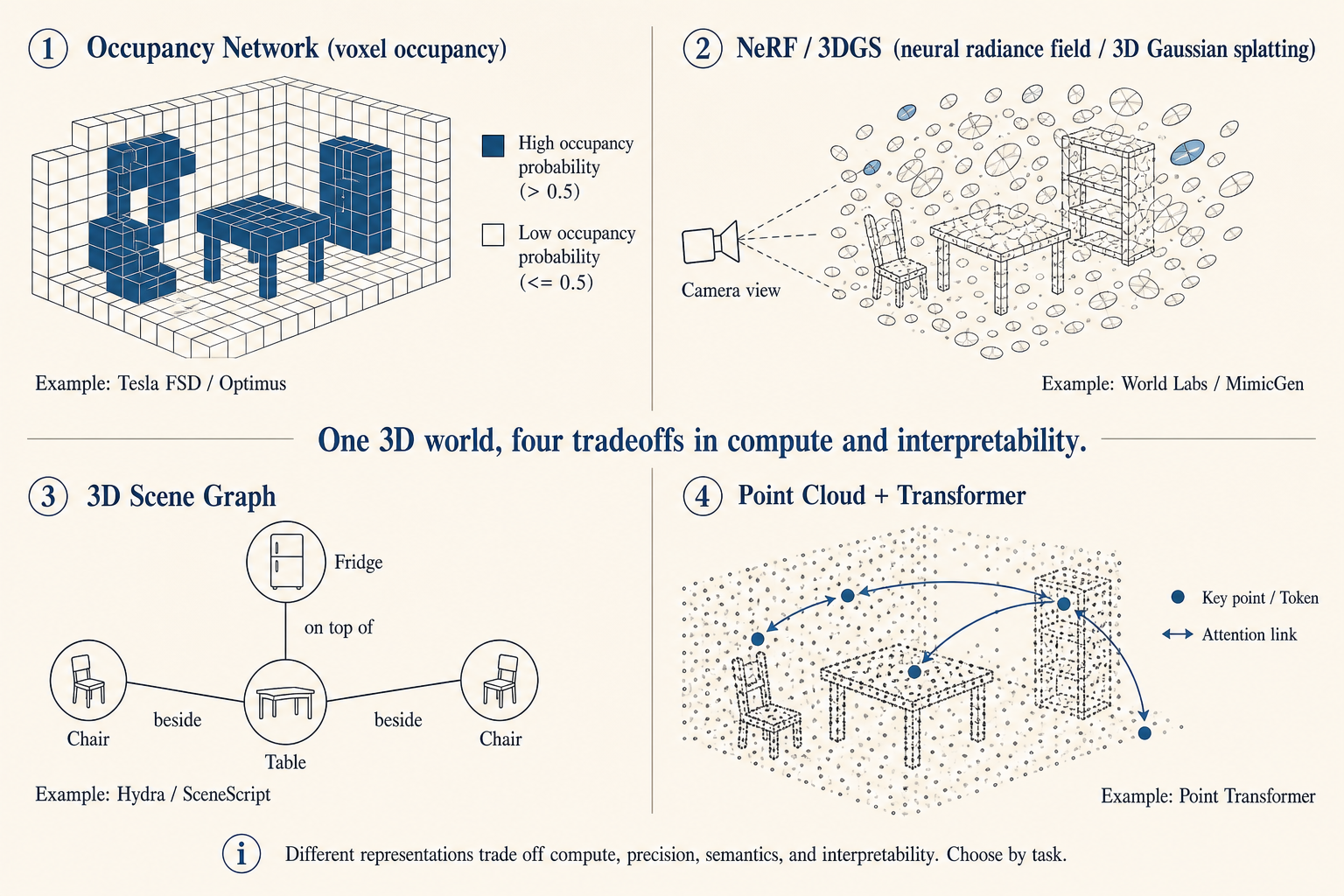
These representations often work together. Low-level obstacle avoidance may use occupancy or a local cost map. Grasping may use point clouds and end-effector poses. Long-running tasks may use a scene graph. Training-data augmentation may use NeRF or 3DGS. The hard part is putting them on the same timeline and in the same coordinate system. Once a 3D scene stops updating, it quickly becomes an old photo.
SLAM and point clouds are good at geometry. They can provide pose and obstacles, but the semantics are weak. The system knows there is a cluster of points ahead. It may not know whether it is a chair or a cardboard box. NeRF and 3D Gaussian Splatting are strong at reconstruction and new-view generation. For robots, the useful question is whether they can bring simulation, data augmentation, and world models closer to real scenes.
A 3D scene graph is closer to long-term memory. It turns rooms, tables, cups, and drawers into nodes. It turns “the cup is on the table,” “the drawer belongs to the cabinet,” and “the keys were last seen near the entryway” into relationships. If a home robot needs to answer “where did I put the wrench last time,” storing only video frames will not be enough.
Spatial memory also has to preserve uncertainty. If the robot saw a cup once, it should not permanently believe the cup is still in that spot. Object names, last observation time, confidence, and visibility all have to be stored together.
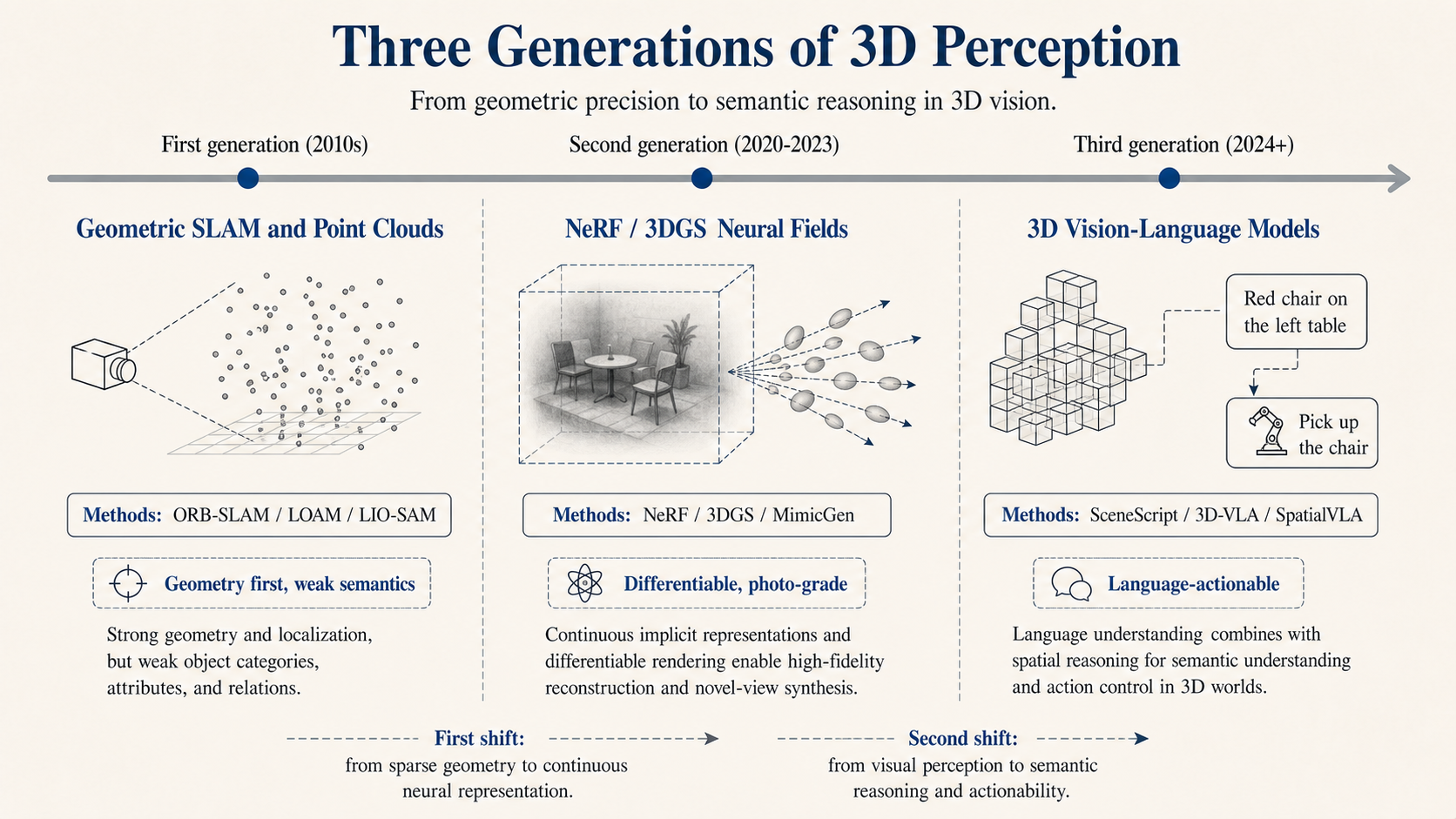
VLA is also moving from 2D toward 3D. Early systems such as RT-2 and OpenVLA mainly connected 2D images, language, and action. That is enough for many tabletop grasping tasks. Once the instruction becomes “take out the blocked blue block,” pixels are not enough. The robot has to know what blocks the blue object, whether it should move the blocker first, and whether moving it will make something else fall.
Work such as 3D-VLA and SpatialVLA tries to combine 3D scenes, SE(3) poses, which describe position and orientation together, and action generation. Figure’s Helix series can work from monocular visual input, but it still has to learn depth, affordance, and object relationships internally. The input can be 2D. The internal representation still has to enter 3D.

Monocular cameras on humanoid robots are also a trade-off. A monocular system can estimate depth from multiple views, motion parallax, and neural networks, but it needs enough data and stable movement. Active depth or LiDAR buys certainty with hardware. Tesla, Figure, Boston Dynamics, and Unitree choose different sensor setups because they trade off visual data, compute, real-time behavior, and safety redundancy in different ways.
This is the boundary of my small robot dog. It can turn language into action, but the action is not in space. It has no pose, no map, and no occlusion handling. A command like “take two steps left” still cannot land.
From Hard-Coded Motions to VLA
My robot dog still runs fixed motions. When I say “sit down,” it loads a preset group of servo angles. It is not generating a new action from vision and language. I only added intent recognition in front of a small motion library.
In embodied AI, VLA, or Vision-Language-Action, is the direction worth studying closely. It feeds vision, language, and robot state into the same model and asks the model to output actions directly. This reduces many hand-written interfaces between visual detection, language understanding, planning, and control. Fewer interfaces also make debugging harder.
| Route | Representative work | How action is represented | What happens on a real robot |
|---|---|---|---|
| Discrete tokens | RT-1, RT-2, OpenVLA | Continuous actions are discretized into tokens | Easy to connect to language models, but precision and sequence length are limited |
| Action chunks | ACT | Predict the next k steps at once | Reduces accumulated error in high-frequency control |
| Diffusion generation | Diffusion Policy, RDT-1B | Generate action trajectories from noise | Fits multimodal actions, such as going left or right around an obstacle |
| Flow matching | pi0, pi0.5, SmolVLA | Generate a continuous action distribution | Faster sampling, better fit for low-latency control |
| High and low-frequency systems | Helix, Gemini Robotics | High-level reasoning decomposes tasks, low-level VLA executes actions | Closer to a brain and cerebellum split |
“Output action” can mean different things. Some models output joint angles. Some output end-effector movement for the hand or gripper. Some output gripper opening and closing. Joint angles are close to the hardware but hard to transfer across robots. End-effector poses are more general, but they need inverse kinematics.
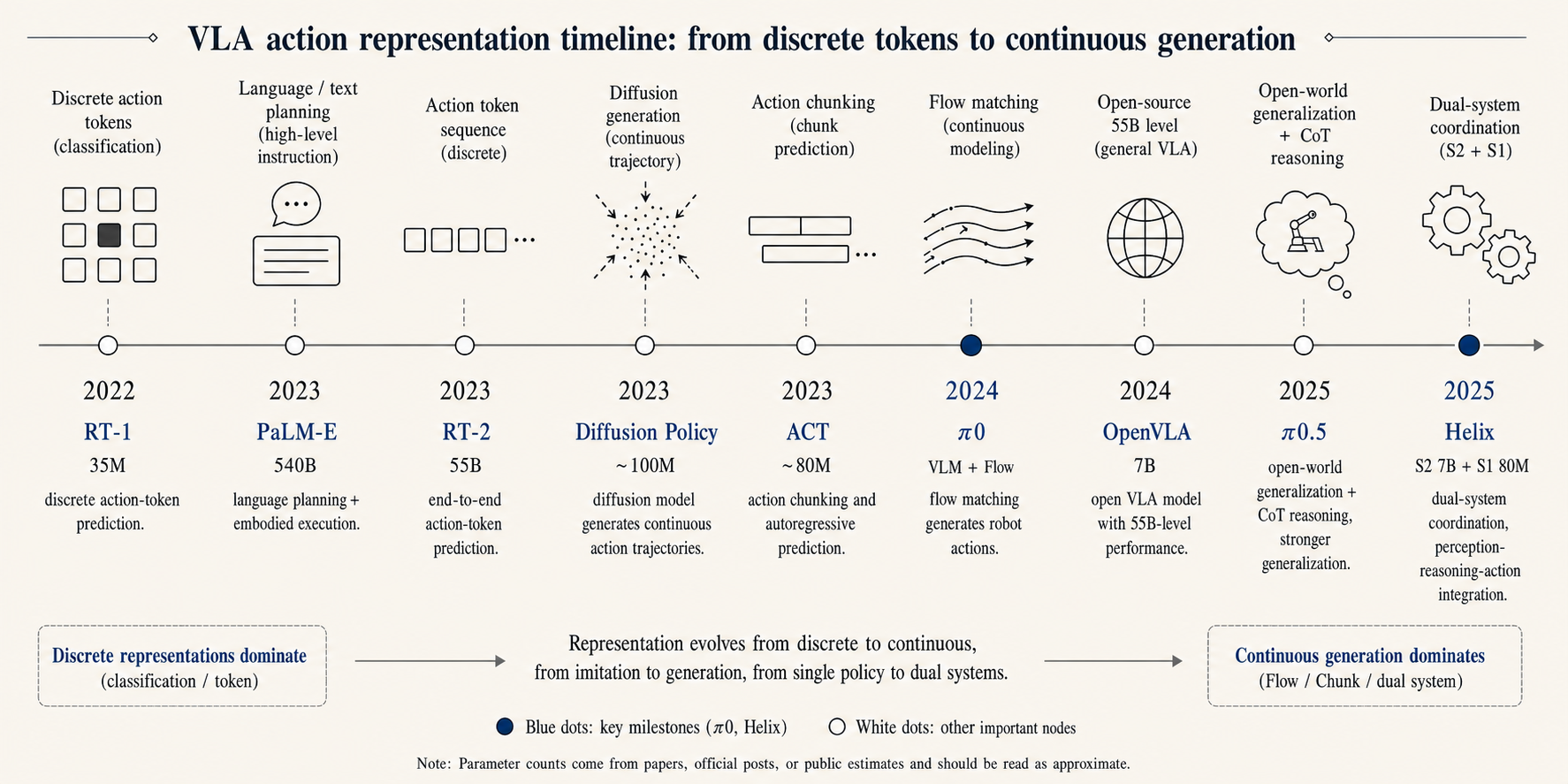
The directions follow a rough timeline. RT-1 came first. It trained a Transformer on 130,000 demonstrations and more than 700 tasks, treating robot control as sequence learning. RT-2 then mixed in internet-scale image-text data, so the model could bring web knowledge into robot control. The cost is clear: compressing continuous joints, poses, and gripper states into tokens loses precision, and more actions make the token string longer.
ACT is more direct. It predicts a small block of actions at once. With ALOHA, two low-cost teleoperation arms can plug in a USB cable, zip a zipper, and fry an egg. It is still many people’s first stop for imitation learning. Diffusion Policy addresses a different problem. When there are several valid ways to avoid an obstacle, ordinary regression can learn an averaged motion that goes straight into it. Diffusion starts from noise and generates actions step by step, which can preserve multiple valid paths.
pi0 uses flow matching. You can think of it as a close relative of diffusion with much faster sampling. pi0.5 pushes generalization into open environments by mixing high-level subtasks, spoken instructions, and web data into training. Physical Intelligence reported that more training environments improved stability in new homes, and that around 100 environments could match training directly in the target environment.
SmolVLA pushes from the other side. It lowers the entry barrier to consumer hardware. It has 450M parameters, uses community data, and can run with fewer than 30,000 episodes. It may not be the strongest model, but it moves VLA out of big-company clusters.
Community data has a practical requirement. Diversity has to cover lighting, camera angles, rooms, and demonstration quality. It is like test data in software engineering: clean data from one lab may be less useful than noisy data that covers more situations.
After 2025, the high and low-level split became clearer. Google DeepMind’s Gemini Robotics is one example. ER 1.6 handles understanding and task decomposition. 1.5 turns each step into action. Google also released an On-Device version for local low-latency use, which can adapt to new tasks with 50 to 100 demonstrations.
This split often looks good in a demo. In a real product it exposes problems. “Organize the desk according to local recycling rules.” The high-level model has to check the rules, split the task, and explain intent. The low-level model has to identify each object and place it in the right container. If the two layers become one black box, a failure is hard to locate.
Figure’s Helix also uses a layered system. In early Helix, S2 was a low-frequency VLM and S1 was a 200 Hz action policy. Helix 02 added an S0 full-body control layer at 1 kHz, putting balance, contact, and coordination into an even faster layer. My robot dog is a toy version of the same idea. A slow model can do understanding, but balance, contact, and coordination need a faster layer.
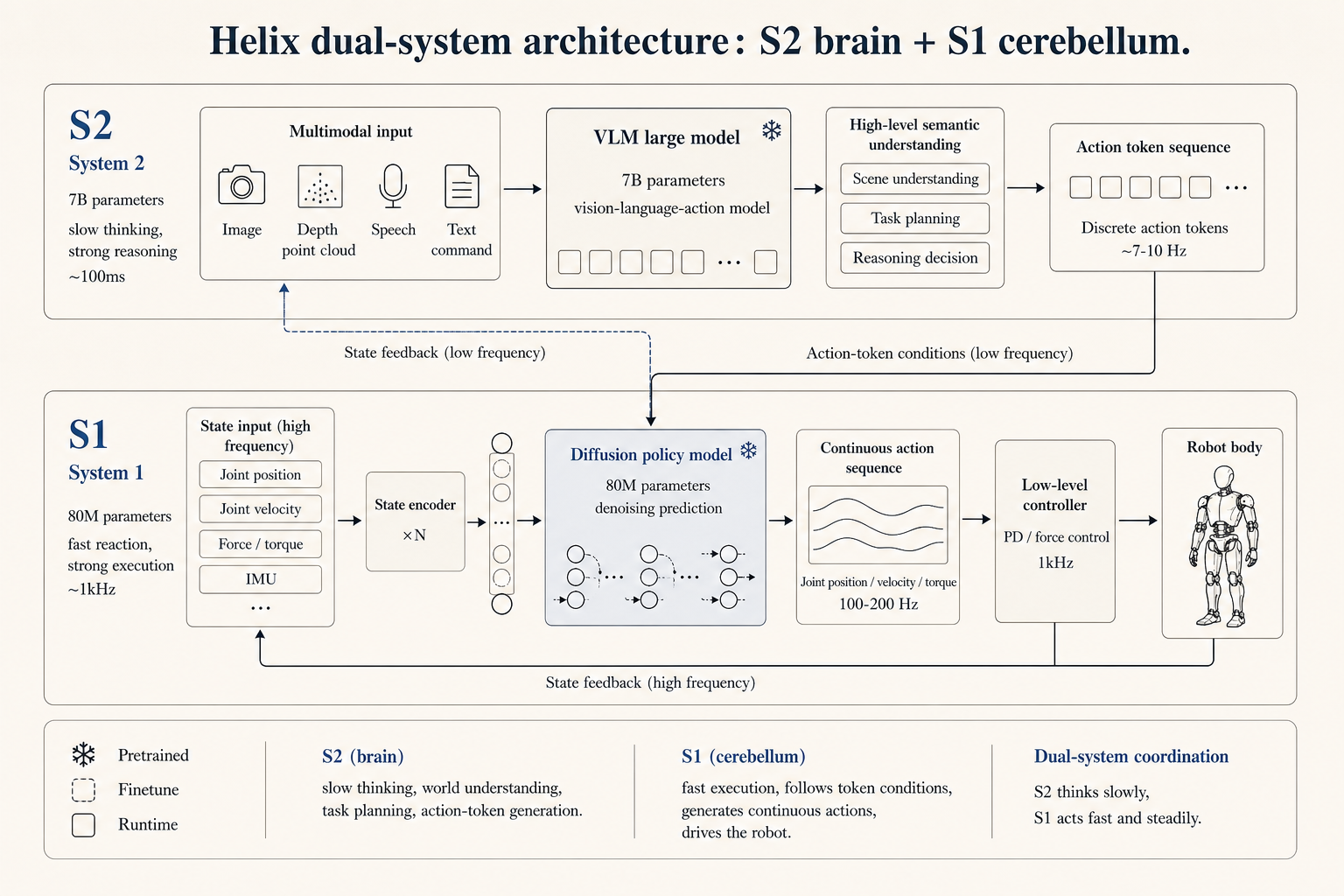
Beyond speech, a robot brain also has to choose an action representation. If actions are too coarse, the robot cannot grasp accurately. If actions are too slow, control becomes unstable. Once actions become discontinuous, real motors and contact amplify the error.
Time, Energy, and Data
When I split a robot control system, I usually think in three parts: brain, cerebellum, and body. In engineering terms, this is a problem of different control frequencies.
| Layer | What it handles | Typical time scale | Common techniques |
|---|---|---|---|
| Brain | Visual understanding, language interaction, task decomposition | 100 ms to 1 s | VLM, VLA, LLM, GPU or NPU |
| Cerebellum | Trajectory generation, balance, motion coordination | 1 ms to 50 ms | MPC, RL, IK, real-time CPU |
| Body | Motor current, encoder feedback, emergency stop | Microseconds to 10 ms | MCU, FPGA, EtherCAT, CAN-FD |
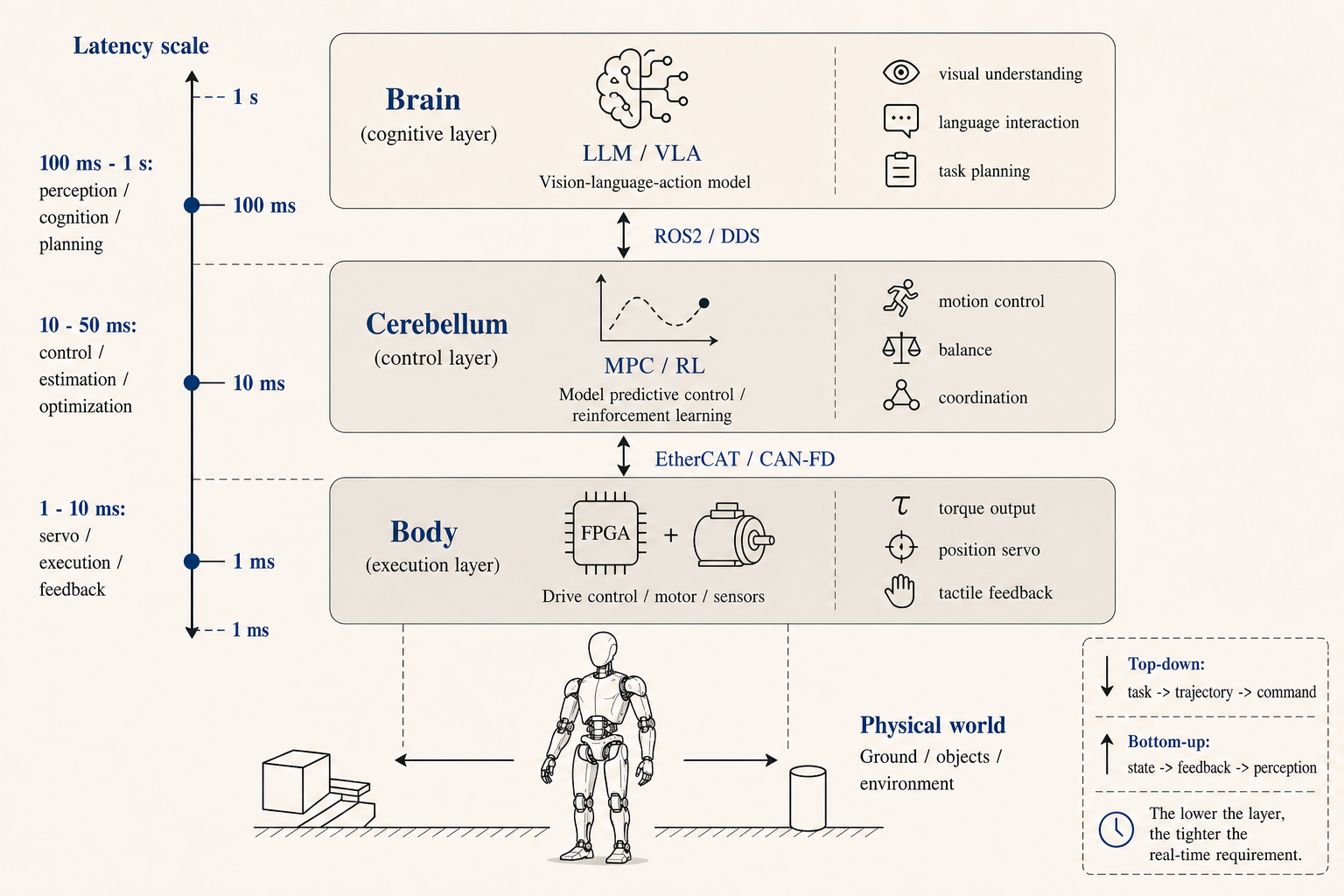
The small robot dog has the same split in a simplified form. DeepSeek dialogue is the brain. The gait sequence inside the STM32 is the cerebellum. PWM and servos are the body. Since it does not do dynamic balance, a 1 to 2 second cloud response is acceptable. On a humanoid robot, a 1 second balance delay is enough to make it fall.
The brain can be slow. When a robot hears “put the cup in the sink,” it can split that into finding the cup, walking over, grasping it, and releasing it. This semantic work does not need 1 kHz. The cerebellum does. A standing and walking human is roughly an inverted pendulum. The control loop often has to run at 200 Hz to 1000 Hz. If it is too slow, a small disturbance can become a fall.
The body layer is even more real-time. Motor control reads encoders, estimates speed, limits current, and stops immediately when something is wrong. Many systems put this layer on a dedicated MCU or FPGA to avoid the scheduling uncertainty of Linux.
Latency looks different depending on where it happens. If the brain is slow, the robot feels sluggish. If the cerebellum is slow, balance suffers and a small touch may knock it down. If the body layer is slow, motors jitter, heat up, and can hit a person.
A pitfall that is easy to underestimate is coordinate frames and timing. The brain and cerebellum may use different coordinate frames. Sensors also run at different speeds: IMUs at hundreds of hertz, cameras at tens of hertz, encoders at thousands of hertz. Calibration and timestamps have to align them to the same time and coordinate system. Once calibration drifts, the state seen by the model no longer matches the real world. The algorithm looks as if it suddenly became worse. Many robot debugging sessions go back to sensors, extrinsics, zero points, and timestamps.

After time comes energy. Robots cannot avoid actuators and batteries. A humanoid robot has dozens of motors. Motors, gearboxes, lead screws, encoders, and drivers are often the most expensive and hardest-to-scale parts of the BOM.
Dexterous hands are especially difficult. Motors, tendons, tactile sensing, wiring, and heat all have to fit into a palm-sized space. That is why many companies keep refining hands. A human uses about 2000 kcal a day, around 2.3 kWh, and can move for a long time. Robots do not have the same passive support from bones and ligaments. Even standing still costs energy because the motors have to hold posture.
The third piece is training data. It is much harder to collect than ordinary large-model data. Text can be crawled. Images can be labeled. Self-driving cars can collect from vehicles on the road. Robot manipulation needs real hardware, a site, people watching, and a defined safety boundary. Once all of that is ready, collection cost is already an order of magnitude higher. The data roughly comes from these places.
| Data source | Strength | Weakness |
|---|---|---|
| Human teleoperation | High-quality actions and clear task semantics | One person usually teaches one robot at a time |
| Autonomous robot runs | Closest to the deployment distribution | Failures have hardware and safety costs |
| Simulation data | Parallel, reproducible, cheap | Friction, deformation, contact, and visual texture differ from reality |
| Human video | Large scale and real objects | Lacks robot action labels and proprioceptive state |
| Synthetic data | Easy to cover long-tail scenes | Still has to prove that it improves the real robot policy |
Simulation tries to avoid the pain of collection, but the real machine is different. Lighting, friction, tolerance, wear, sensor noise, and motor heat are clean in simulation and messy on hardware. A steadier approach is to train the policy in simulation until it stops making low-level mistakes, then calibrate with a small amount of real data, feed failed samples back, and train again. A pure simulation path tends to underestimate contact and sensor error. Simulation data alone is far from enough.
Which layer can be slow? Which layer must be real-time? Which tasks can use a GPU? Which ones must stay on the MCU? Compared with pure software, there are many more layers to hold in your head.
Tesla Optimus as an Engineering Sample
I like Tesla and bought the stock early, so I am not neutral when I look at Optimus. I still want to write about it because it puts FSD transfer, vision-only sensing, end-to-end training, in-house actuators, factory trials, and large-scale manufacturing into one machine. Once you study it piece by piece, several questions become more concrete: how long does a dexterous hand take to move from demo to reliability, how failed samples add contact data, and how manufacturing turns actuators, wiring, sensors, and batteries into a maintainable product.
The numbers in the table come from Tesla AI Day, earnings calls, and third-party technical summaries. They are public statements and targets, not proof of shipped capability. I still remember how many robotics companies studied the AI Day slides and videos frame by frame. That alone says a lot.
| Item | Early public statement | Gen 3 related statement | Why it matters |
|---|---|---|---|
| Body DoF | AI Day 2022 disclosed 28 base DoF, excluding the hands | Still centered around 28+ body DoF | Body motion is already complex. Much of the visible change is in hands and forearms |
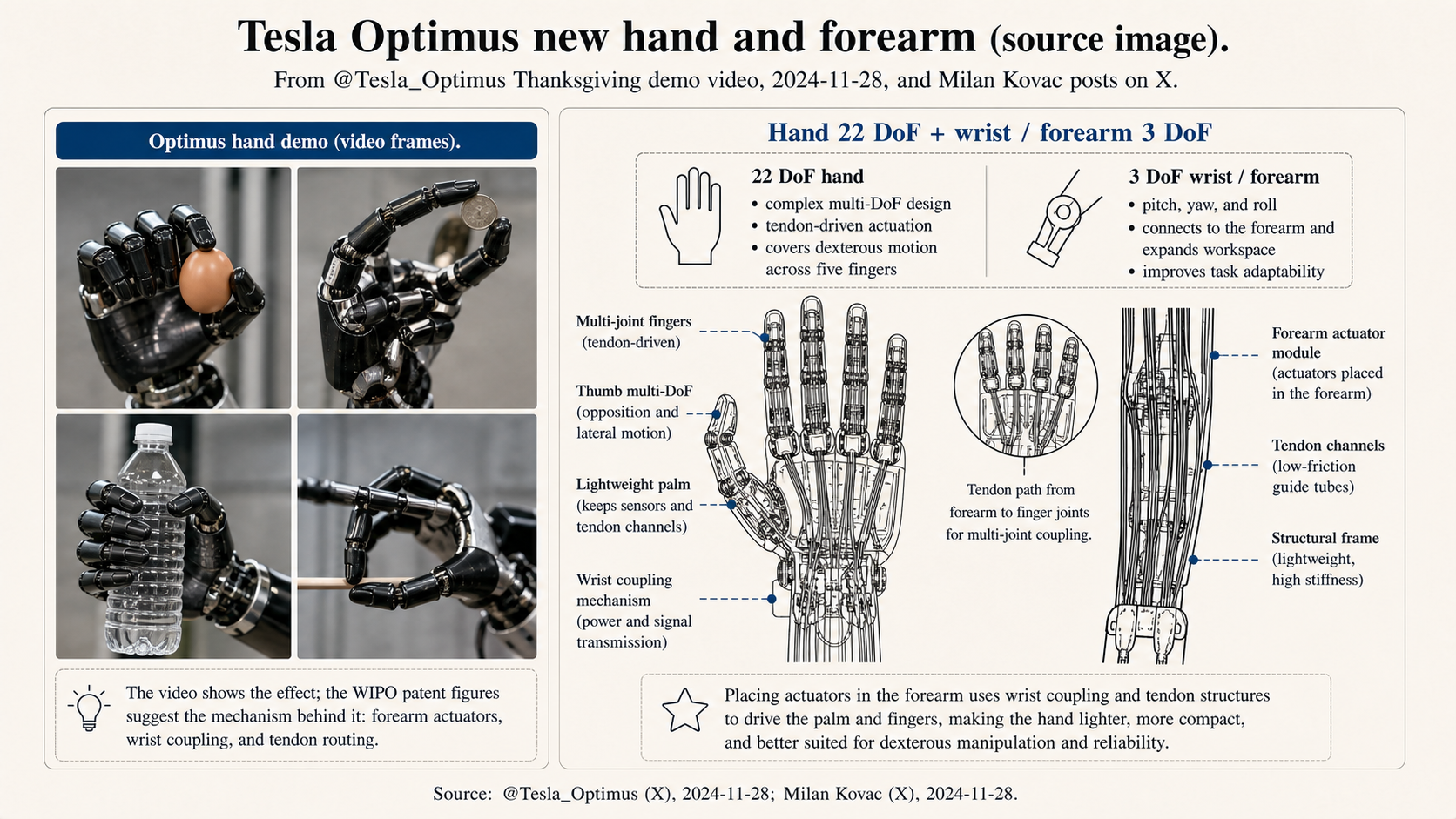
| Hand DoF | 11 DoF and 6 actuators per hand | Next-generation hand and forearm were publicly described as 22 DoF. Third-party summaries mention 25 actuators per hand | More dexterous manipulation, plus harder wiring, heat, lifetime, and calibration |
| Compute platform | A trunk-mounted computer similar to the vehicle FSD computer | AI5 has been described publicly as supporting larger on-device models and inference | Long-term cloud dependence is limiting. Edge energy efficiency constrains the product early |
| Cost target | AI Day 2022 mentioned a long-term idea below USD 20,000 | Earnings calls continued to discuss a USD 20,000-level target at scale | This depends on actuators, magnets, wiring, and assembly yield. The model is only one part |
| Deployment stage | First tested inside Tesla factories | Multiple earnings calls mention internal use, design iteration, and later production-line targets | The factory works like a training and validation field. External sales timing still needs caution |
The hand upgrade may look small, but in robotics it is a large change. Factory tasks such as tightening screws, plugging connectors, moving parts, and attaching labels, and home tasks such as picking up cups, opening doors, and folding clothes, cannot be solved by arm motion alone. Fingers need enough contact points. They also need to know whether an object is slipping, fragile, and where the contact surface is.
A Finger Without a Pin
On April 16, 2026, a third-party teardown discussed a set of WIPO publications for Tesla’s hand and forearm. A patent is not a production design, but WO 2026/080693, “Joint Assembly for Robotic Appendage,” shows an interesting structural trade-off. I saw the report on X at the time and remembered it clearly.
The teardown described a design that avoids a traditional pin hinge. A flat composite element sits between two phalanges. It has elastic layers on the top and bottom, with a very thin reinforcement layer in the middle. The material candidates include Vectran and Nitinol. Vectran is a liquid-crystal polymer fiber. Nitinol is a nickel-titanium superelastic alloy. Both can help create directional stiffness.
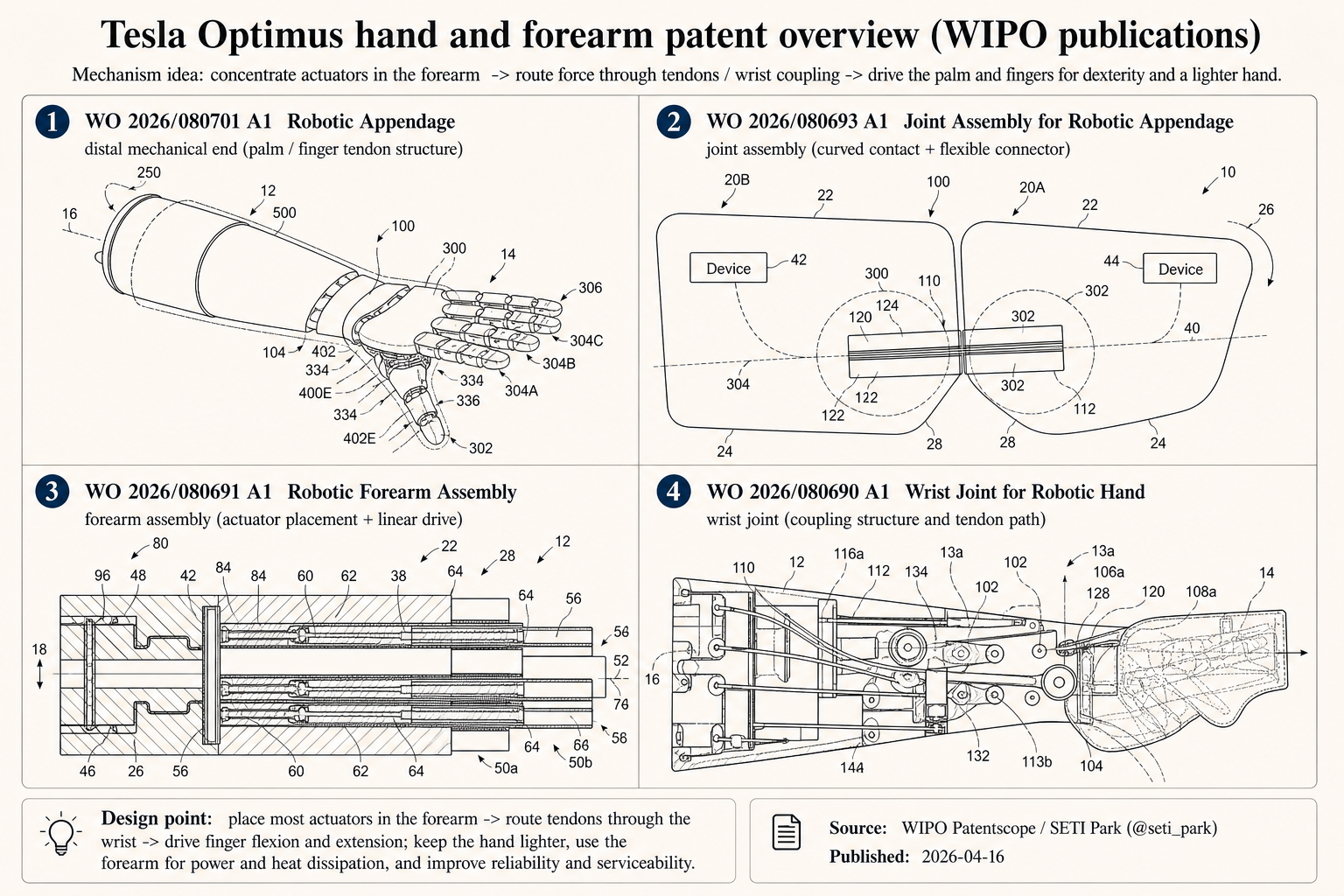
The design tries to control bending direction. The finger should be soft when it bends, but stiff in extension, compression, shear, torsion, and side swing. A traditional pin hinge limits extra degrees of freedom with geometry. This approach uses anisotropic stiffness. It has three possible engineering benefits. The phalanges can form something close to rolling contact, with the rotation axis moving as the angle changes, which is closer to a real finger. The elastomer provides its own return force, so a separate return spring may not be needed. The tendon can pass through the neutral plane, reducing fatigue from repeated bending.
This looks like mechanical design, but it touches a whole chain of dexterous-hand problems. A joint structure affects finger return, tendon routing, wrist layout, forearm space, assembly tolerance, and repair. Whether it can stay consistent after thousands of grasps per day cannot be read from a demo. It has to be tested in real work.
How Optimus AI May Be Built
Tesla keeps emphasizing that Optimus and FSD share roots. AI Day 2022 said the computer inside the robot torso came from the vehicle FSD computer, and that the software stack reused object detection, occupancy networks, indoor navigation, and motion planning from the car. Some third-party summaries describe Optimus as an end-to-end system with 8 camera inputs and 78 actuator outputs.
Tesla is more likely building a unified learned system than a single end-to-end neural network. Full FSD construction involves 48 networks. The engineering implementation is probably a multi-task, multi-head architecture with shared representations.
| Layer | Capability often seen in public material | What it gives the robot |
|---|---|---|
| Visual input | 8 automotive-grade cameras, vision-only route | Lower sensor cost, with depth and redundancy handled by data and models |
| 3D representation | Occupancy Network, depth estimation, 3D reconstruction | Turn 2D views into traversable space, obstacles, and object locations |
| Task understanding | Grok or a language layer handles instructions | Turn user language or factory tasks into executable steps |
| Motion and manipulation | Motion planning, manipulation planning, balance control | Turn target poses into continuous body and hand motions |
| Execution output | Third-party summaries mention 28 body actuators plus 50 hand actuators | A high-dimensional action space, with harder debugging and safety than self-driving |
The action space in self-driving is small: steering, throttle, and braking cover most of it. A humanoid robot is different. If Optimus has 78 actuators, every time step has to coordinate body, arms, fingers, balance, and contact. If a cup slips slightly, finger force, wrist motion, arm trajectory, and center of mass all need to adjust together.
An end-to-end direction can remove many hand-written interfaces between vision, language, space, and action, allowing them to influence one another through training. The cost is debugging. When the robot grabs the wrong part, was the depth estimate wrong, the object semantics wrong, the action head wrong, or did the actuator fail to track? An engineering system still needs logs, state replay, safety controllers, and interpretable intermediate signals.
If I split Optimus as an engineering system, I would start with four interfaces.
| Interface | Input | Output | How to evaluate it |
|---|---|---|---|
| Vision to 3D | Multi-camera images, body pose | Occupancy, object positions, reachable space | Stability under occlusion, reflection, narrow passages, and low-texture objects |
| Language to task | Human instruction, factory SOP, current scene | Subtask sequence and failure recovery policy | Whether changed wording still produces a reasonable process, and whether failures can be replanned |
| Task to action | Subtasks, end-effector targets, contact state | Body, arm, and finger trajectories | Frequency, latency, jitter, and contact force within safety bounds |
| Action to execution | Joint targets, current limits, sensor feedback | Execution result, fault code, emergency-stop state | Drift after long repetition, and whether faults can be located |
The same four interfaces also map onto my robot dog, only at a much smaller scale. My dog only has language-to-fixed-action and action-to-PWM. It lacks vision-to-3D and contact state. Optimus has to make all four interfaces work at the same time, and any failure at one layer may be swallowed by the unified model.
Where Data Comes From, and Why Mass Production Is Hard
Tesla’s advantage is often summarized as fleet data. That is only partly true here. Fleet data can give Optimus visual common sense, spatial understanding, lighting adaptation, dynamic-object prediction, and occupancy representations. Cars do not handle cup friction, and they do not use fingers to judge whether a cardboard box has collapsed. What robots lack most is contact data from the physical world. Based on public material, Optimus data mainly comes from four sources.
| Data source | What it adds | What is still missing |
|---|---|---|
| Vehicle fleet | Visual common sense, spatial understanding, occupancy representations | Grasping, force control, touch, contact failures |
| Human first-person demonstrations | Task semantics, hand details, tool use | Robot proprioception and real execution error |
| Digital Dreams or neural world simulator | Long-tail scenes, lighting, object placement, initial-state variants | Physical consistency of generated data still needs real-robot validation |
| Factory Optimus online feedback | Successes and failures closest to deployment | Limited by robot count, task boundary, and safety constraints |
That is why human operators wear helmets and backpack cameras to collect data on site. I also recently saw Chinese embodied-AI companies working with housekeeping companies, asking workers to clean while wearing sensors and cameras. These partnerships are all trying to capture physical-world contact data. 
Robot data is much slower than self-driving data. A vehicle fleet can collect from cars all over the road every day. Teleoperation usually means one person teaching one robot at a time. Autonomous real-robot collection is even slower. Failures wear hardware, interrupt production lines, and add safety risk. This is hard, but I still like the direction.
The gap between robotics companies will gradually show up in how fast they collect samples, train, and change hardware. A company that can collect failed samples cheaply and steadily, then feed them into the next training and hardware loop, will widen its iteration lead.
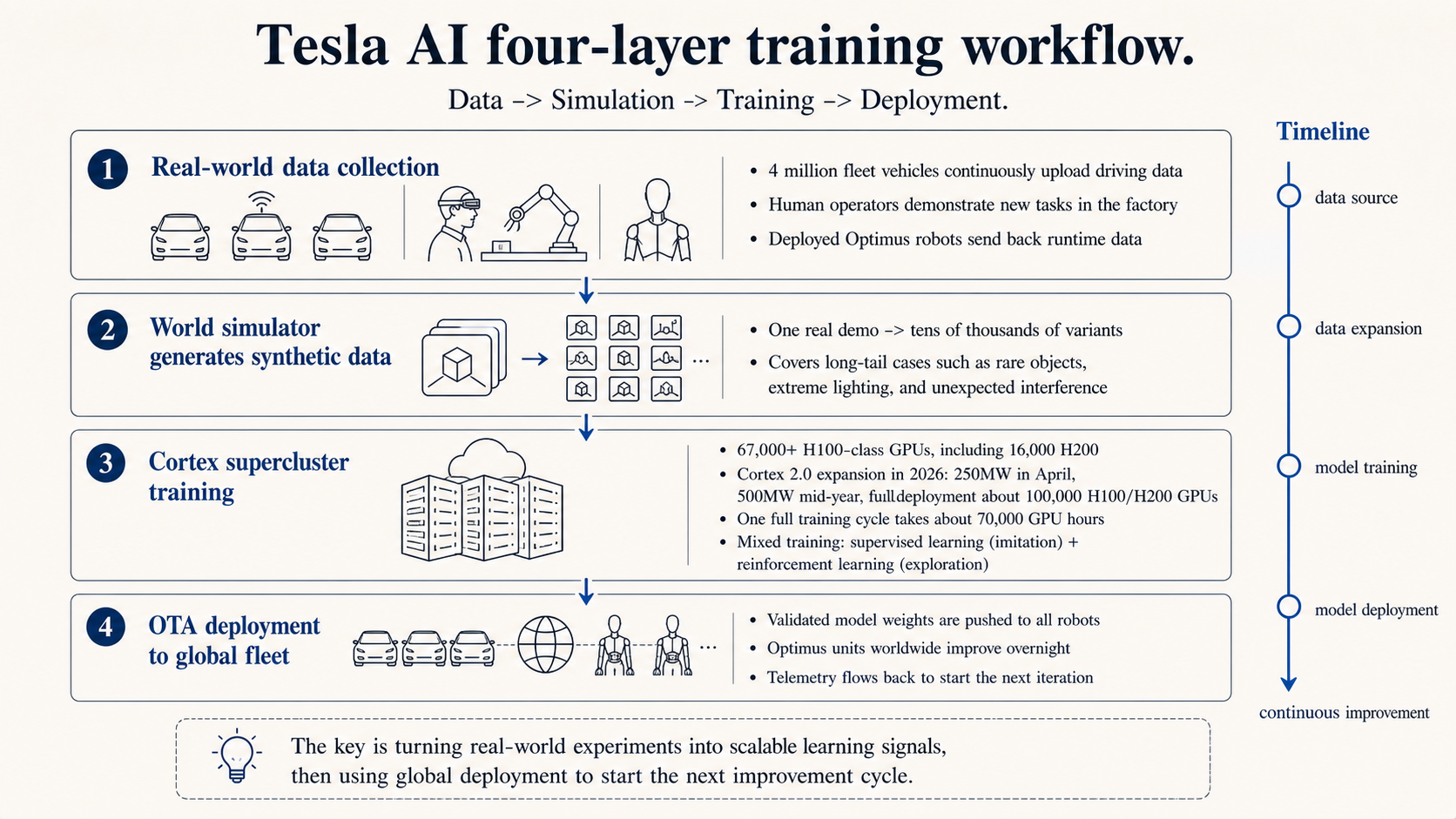
Data is one barrier. Manufacturing is another.
Tesla discusses Optimus on almost every earnings call. As an investor, I try to separate what they say from what has been achieved. If you connect the public statements from 2024 to 2026, you can see continuous movement and the recurring bottlenecks.
| Public statement | Where it gets stuck |
|---|---|
| Use Optimus inside Tesla factories first | The factory is a task field, a data field, and a safety boundary |
| The robot is not design-locked yet | Hardware finalization is still moving. Model iteration speed does not equal whole-machine iteration speed |
| Production-line target moves from 1,000 units per month to higher scale | The bottleneck is actuators, batteries, wiring, assembly, and quality-control yield |
| Target cost below USD 20,000 after scaling | This depends on a new supply chain. Software cost reduction is only one part |
| Rare-earth permanent magnets were named as an Optimus constraint | Actuators are constrained by materials and supply chains |
These constraints matter more than a delivery year. Humanoid robots cannot wait for the model to finish training before the production line starts. Hardware, data, and manufacturing usually move together. If the hand design changes, the forearm structure, wiring, tactile sensors, controllers, and supply chain move with it. If actuator yield is unstable, the slowest part drags down production targets.
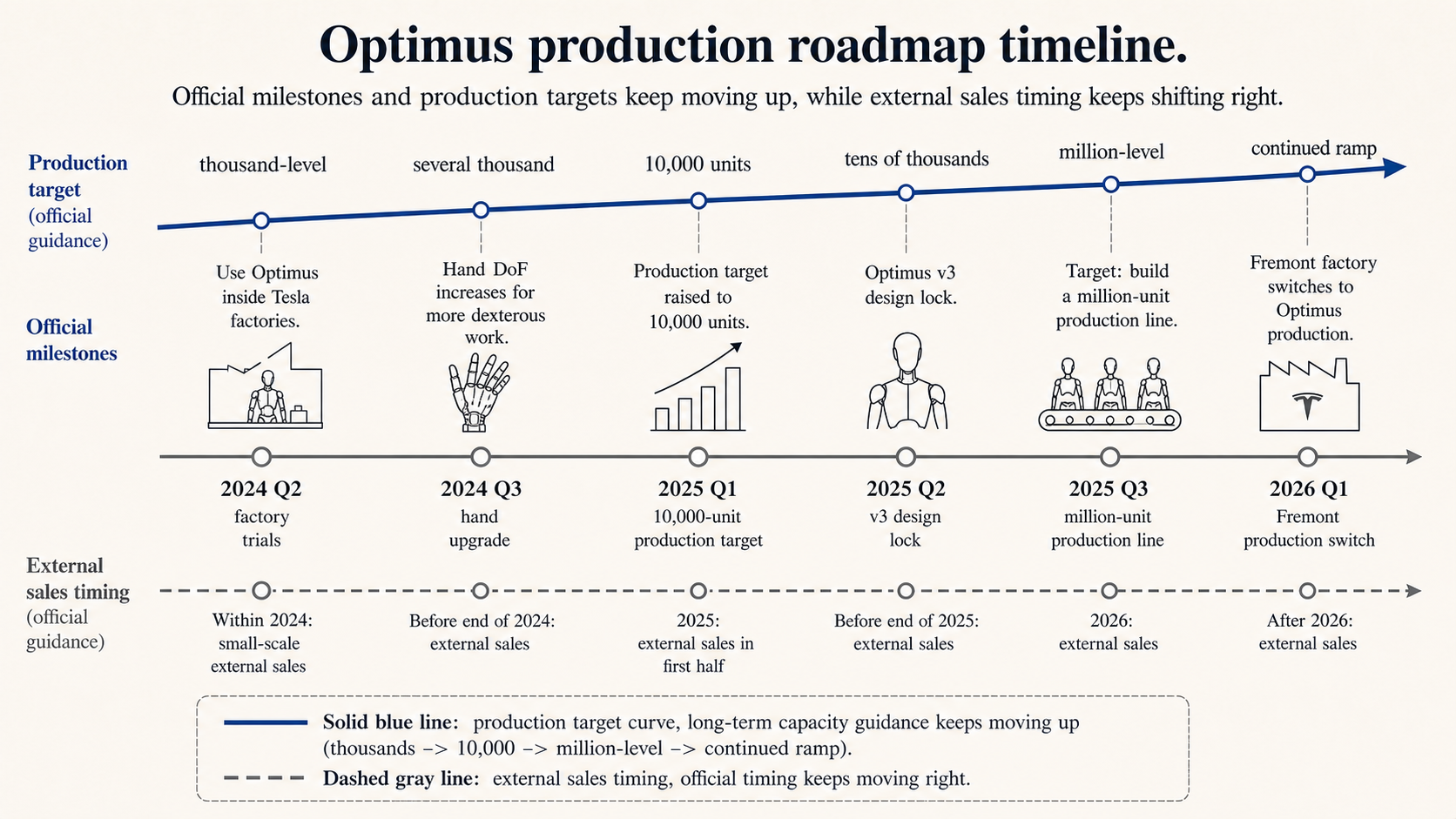
From public material, Tesla is betting on a combination of real-world data, manufacturing scale, and vertical integration. FSD gives it a visual and training-infrastructure base. Factories give it controlled tasks and feedback. Manufacturing gives it a cost-down path. If hand reliability, actuator cost, safety protection, or real workstation ROI gets stuck, those advantages will be hard to turn into product.
The next useful checks for Optimus are concrete: long-term reliability of the hand structure, how fast failed samples return to training and real-robot validation, whether the model exposes debuggable interfaces, and whether actuator and supply-chain support can match the production-line targets. If Tesla’s route works, it will not be because of the model alone. It will be because fleet visual experience, factory tasks, world simulators, training clusters, and manufacturing all connect.
Different Routes Across Companies
Many companies are building humanoid robots now, but their routes and bets differ a lot.
| Player | Route | Main bet | What to watch |
|---|---|---|---|
| Tesla Optimus | Vision-only, FSD transfer, factory trials, in-house actuators | Failed samples and manufacturing scale | Hands, actuator cost, real workstation ROI |
| Figure | Helix and Helix 02, full-body VLA and factory tasks | On-device VLA and long-horizon loco-manipulation | Stability outside demos, maintenance cost |
| Google DeepMind | Gemini Robotics, high-level ER plus low-level VLA | General multi-step reasoning connected to robot actions | Generalization and safety boundaries across partner hardware |
| NVIDIA | Jetson Thor, Cosmos, Isaac, GR00T | Chips, simulation, world models, and foundation-model toolchains | Whether the stack can be reused reliably across robots |
| Boston Dynamics | Traditional control base plus AI augmentation | Reliable motion control and industrial deployment | Cost and general manipulation ability |
| Unitree | Cost-effective hardware, strong motion ability, developer market | Expand the hardware base through low prices | Software community and safety-task capability |
| AGIBOT | Multiple form factors, datasets, full-stack platform | Domestic supply chain and real task data | Publicly verifiable task coverage and continuous operation |
These seven companies split into two groups. One group builds complete robots. Tesla, Figure, Unitree, and AGIBOT cover hardware and models themselves. The other group does not bind itself to a single body. Google DeepMind builds the intelligence layer that can connect to different robots. NVIDIA sells compute, simulation, world models, and foundation-model tooling to everyone. The first group bets on whether data and manufacturing can lock together. The second bets on whether its layer can transfer across robot bodies.

The platform route sounds easier, but the interface boundary is risky. If the upper instruction is too abstract, the lower layer cannot execute it. If the lower layer fails without a clear reason, the upper layer cannot replan. It is the same problem that showed up in the VLA section.
VLA is not the only route. Boston Dynamics does not lean on the large-model narrative, yet electric Atlas and years of motion-control work still get it into factory logistics. Industrial sites care about cycle time, failure rate, and safety certification more than demos. In China, the most practical signals are price and supply-chain speed. Unitree G1 officially starts at USD 13,500. That price can quickly expand the hardware base. Whether it can handle general tasks and stay reliable for long periods still needs time.
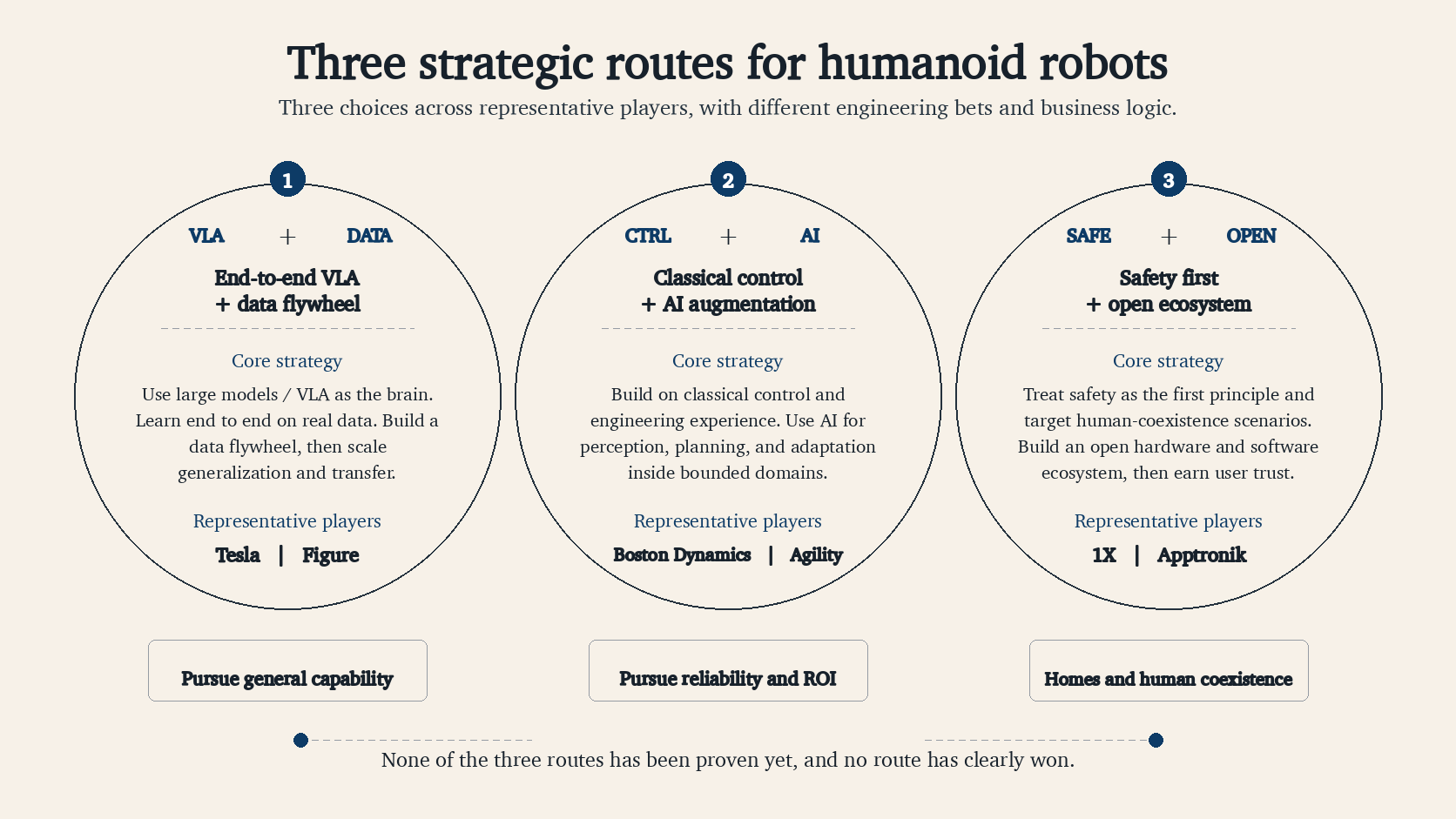
Behind these routes are three trade-offs. Factories are widely treated as the first stop because the environment is controlled, ROI can be calculated, and task boundaries can be limited. Homes are the hardest. The environment is messy, users tolerate little error, and the robot has to be quiet, safe, and privacy-aware. Platform companies choose to sell the toolchain first because most robotics companies lack data, simulation, edge compute, and training frameworks.
Moving From Software Toward Embodied AI
If you are also a software engineer and want to keep studying embodied AI, these system-level areas are hard to avoid.
- Embedded and real-time systems: GPIO, PWM, I2C, UART, SPI, timers, interrupts, RTOS
- Robot kinematics: coordinate frames, forward and inverse kinematics, Jacobian, end-effector pose
- Control basics: PID, MPC, state estimation, sampling frequency, latency, stability
- Perception and SLAM: camera model, depth, IMU, LiDAR, extrinsics, time synchronization
- Imitation learning and reinforcement learning: behavior cloning, ACT, Diffusion Policy, reward, Sim2Real
- Data engineering: teleoperation, episode format, video-state synchronization, annotation, evaluation
As a stack, it runs from chips, actuators, and sensors up to algorithms and systems. Looking only at models hides many of the hard problems. Looking at the whole stack makes it clearer where each problem sits.
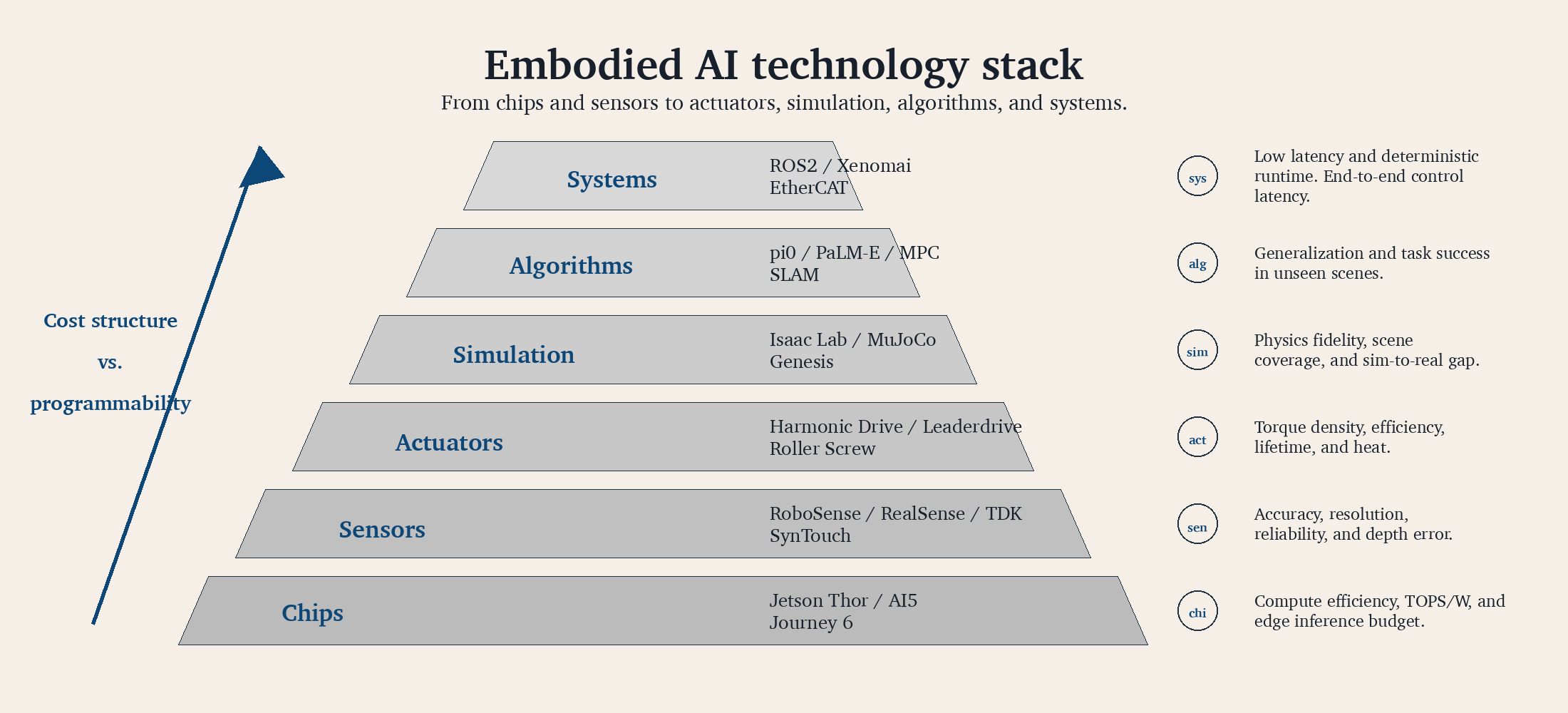
My current way of connecting the material is this: start with a small hardware project like the robot dog, because it ties together cloud-edge collaboration and local action. Wake-up, networking, model calls, capability descriptions, serial protocols, action execution, and status return can all fail in one small system. The project is not large, but every part can fail in a real way. Solving those failures one by one gives the most honest sense of exploration.
After running cloud-edge collaboration and MCP once, ACT and ALOHA become easier to read. Low-cost teleoperation and action chunking make more sense. Diffusion Policy then explains why actions sometimes need to be modeled as distributions. RT-1, RT-2, Open X-Embodiment, and OpenVLA connect VLA with cross-embodiment data. Finally, pi0, pi0.5, SmolVLA, Gemini Robotics, Helix, and GR00T N1.5 show how industry is trying to combine high-level reasoning, low-level action, and edge deployment.
If I had to compress embodied AI into four words, I would use perception, space, action, and torque. The difficulty roughly increases in that order. AI perception is already strong. Spatial ability is still catching up. Action has learned a little. Torque brings the work back to motors, structure, contact, and power. The closer AI moves to the physical world, the less the model can solve alone. More of the remaining work becomes hardware.
References
Models and Algorithms
- RT-1: Robotics Transformer for Real-World Control at Scale, Google Robotics, 2022.
- RT-2: New model translates vision and language into action, Google DeepMind, 2023.
- Diffusion Policy: Visuomotor Policy Learning via Action Diffusion, Columbia + MIT CSAIL, 2023.
- Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware, ACT / ALOHA, 2023.
- Open X-Embodiment, Google DeepMind + 33 institutions, 2023.
- OpenVLA: An Open-Source Vision-Language-Action Model, Stanford + Physical Intelligence + Google DeepMind, 2024.
- pi0: A Vision-Language-Action Flow Model for General Robot Control, Physical Intelligence, 2024.
- pi0.5: a VLA with Open-World Generalization, Physical Intelligence, 2025.
- SmolVLA: Efficient Vision-Language-Action Model trained on LeRobot Community Data, Hugging Face, 2025.
- Gemini Robotics, Google DeepMind.
- Gemini Robotics On-Device brings AI to local robotic devices, Google DeepMind, 2025.
Industry, Hardware, and Toolchains
- Helix: A Vision-Language-Action Model for Generalist Humanoid Control, Figure AI, 2025.
- Introducing Helix 02: Full-Body Autonomy, Figure AI.
- NVIDIA Jetson Thor, NVIDIA.
- Cosmos World Foundation Model Platform for Physical AI, NVIDIA Research, 2025.
- GR00T N1.5, NVIDIA GEAR.
- LeRobot, Hugging Face.
- SO-ARM100, SO-100 / SO-101 low-cost robot-arm hardware.
- xiaozhi-esp32, open-source ESP32 AI voice assistant.
- Genesis, open-source physics simulation platform.
- NVIDIA Isaac Lab, robotics learning framework.
- Tesla AI Day 2022 transcript, early Optimus technical disclosure.
- AI Training for Tesla Optimus Explained, third-party summary of Optimus AI training, data sources, and world simulators.
- Tesla Earnings Call Transcripts, public transcript aggregator for Optimus statements from 2024 Q2 to 2025 Q3.
- The Pinless Finger: What Tesla Put Where the Hinge Should Be, third-party WIPO patent teardown of Optimus Gen 3 hand and forearm.
- Unitree G1, Unitree official store.
More Reading
If you want to keep reading this AI engineering series, these earlier long posts are a good order:
- What People Miss About Claude Code: Architecture, Governance, and Engineering Practice
- What People Miss About Agents: Principles, Architecture, and Engineering Practice
- What People Miss About Large-Model Training: Principles, Paths, and New Practice
- What People Miss About AI Coding: Getting Started, Use Cases, and Practice for Non-Engineers
- What People Miss About GEO: Principles, Practice, and Trade-offs in AI Visibility
The first draft was completed in May 2026 and kept being revised in June. Embodied AI is moving quickly, so some numbers and product progress may continue to change. If you find an error, please let me know.